
The Interoperability Paradox in Healthcare
Healthcare has spent the better part of a decade investing in interoperability. FHIR has matured into a production-ready standard. The CMS Interoperability and Patient Access Final Rule has been in force for several years. The 21st Century Cures Act has compelled both payers and providers to expose patient data through standardized APIs. Health information exchanges have grown in coverage and reliability. By any reasonable accounting, the plumbing of data exchange has improved significantly.
Yet the operational reality inside most healthcare organizations remains stubbornly familiar. The same patient appears as three different records across the EHR, the patient access portal, and the population health system. The same provider has subtly different addresses and credentials across the credentialing system, the claims system, and the public NPPES registry. The same medical device is catalogued under different identifiers in the materials management system and the regulatory submissions repository. Standards have moved the data but the identity still remains fragmented.
That is the paradox this article addresses. Standards-based interoperability has solved the syntax problem and, in many cases, the semantic problem. It has not solved the identity problem. Without a master data layer that establishes a single, trusted identity for each patient, provider, payer, product, and facility, the data that now flows freely between systems is technically interoperable yet operationally fragmented. The downstream consequences are familiar to anyone who has worked on a healthcare analytics or AI initiative: duplicate records that distort cohort definitions, fragmented care histories that compromise clinical decision support, and inconsistent provider directories that undermine network adequacy reporting.
Master data management is the operational layer that makes the standards-based syntactic and semantic interoperability deliver on their promise. The architecture pattern that supports this layer most naturally is a lakehouse-native MDM built on Databricks, where data quality, matching, survivorship, stewardship, and governance share a single substrate. The sections that follow describe how this architecture is composed and why each piece matters.
Three Layers of Healthcare Interoperability
Conversations of interoperability frequently mix up three separate concepts. By distinguishing between them, it becomes clearer where MDM fits and why it's important.
Syntactic Interoperability
Syntactic interoperability concerns the structure and format of exchanged data. The question it answers is whether the receiving system can parse the message it has received. The standards that operate at this layer include FHIR R4 for clinical and administrative resources, HL7 v2 for traditional clinical messaging, X12 EDI for claims and eligibility transactions, CDA for clinical documents, and DICOM for imaging. When these standards are implemented well, structured data moves between systems with minimal custom integration.
Semantic Interoperability
Semantic interoperability concerns the meaning of the data that has been exchanged. The question it answers is whether both systems mean the same thing by what they sent. Two systems can exchange a FHIR Observation resource with full conformance to the specification and still disagree about what was measured if one is using a local lab code and the other is using LOINC. The standards that operate at this layer include SNOMED CT for clinical findings and procedures, LOINC for laboratory and clinical observations, ICD-10 for diagnoses, RxNorm and NDC for medications, and UCUM for units of measure.
Operational Interoperability
Operational interoperability concerns the identity of the entities that the data describes. The question it answers is whether two records refer to the same real-world entity, regardless of which system produced them. This is the layer at which master data management lives. The reference data that supports it is partially external (NPPES for providers, GUDID for medical devices, USPS for addresses) and partially internal (master identifiers, cross-reference tables, golden records). The disciplines that support it are data quality, entity resolution, survivorship, and stewardship.
Healthcare organizations have invested heavily in the first two layers and comparatively little in the third. The result is that the syntax and semantics of data exchange have improved while the underlying identity problem has stayed broadly where it was twenty years ago. MDM serves as the solution for this imbalance.
The Five Master Data Domains
Healthcare is uniquely multi-domain in its master data needs. A single MDM initiative rarely covers everything, and the order in which domains are tackled has significant implications for cost, risk, and value. The five domains described below each have distinctive matching characteristics, authoritative external references, and consequences for getting wrong.
Patient and Member
Patient MDM presents the greatest challenges among the five domains. Identifiers tend to be unreliable, demographic attributes can change over time, and erroneous merges carry significant clinical risks. While duplicate patient records may result in inconvenience, the incorrect merging of two patients constitutes a serious safety incident. Therefore, adopting a conservative approach in this domain is imperative.
Provider
Provider MDM is relatively manageable due to the presence of reliable external references. The NPPES NPI registry offers a consistent national identifier, the DEA registration system tracks prescribers of controlled substances, and state licensing boards release information about license status and disciplinary actions. The challenges mostly stem from group practice connections, several practice locations, and frequent changes in credentials, not from issues with identity itself.
Payer and Plan
Payer MDM is frequently underestimated, despite its significant impact on claims analytics, network management, and value-based care reporting. A single payer can be represented by multiple legal entity names across claims, contracts, and provider directories, often utilizing various identifiers depending on the specific context.
Product
Product MDM in healthcare combines the standard challenges of any product domain with the regulatory specificity of medical devices and pharmaceuticals. Medical devices carry UDI identifiers registered in the FDA GUDID, drugs carry NDC codes, and laboratory tests reference standard panels and analytes. For a diagnostics manufacturer or pharmaceutical company, product MDM is often the highest-value first domain.
Location and Facility
Facility MDM includes hospitals, integrated delivery networks, purchasing groups, ambulatory sites, retail pharmacies, and home health locations. It is the domain that most often interacts with the other four: providers practice or work at a facility, patients are treated at a facility, products are shipped to a facility and a payers contract with a facility.
Why Healthcare MDM Is Harder
The matching problem in healthcare has a unique structure compared to similar challenges in other domains due to the below key features:
Weak Identifiers - While most consumer industries are able to rely on a select group of robust identifiers such as email addresses, phone numbers, account numbers, or government-issued IDs, healthcare matching frequently operates without access to these resources. Patient matching typically depends upon combinations of name, date of birth, address, and partial identifiers; however, these elements can change over time and are often recorded with varying levels of accuracy across different systems.
Strict Regulatory & Compliance Needs - Regulatory constraints determine which attributes can be utilized. HIPAA limits which identifiers may be kept and shared, while various states have stricter rules regarding the use of biometric data, genetic information, and reproductive health data. Relying on a matching strategy that uses forbidden attributes is not a valid approach.
Minimising False Positives - The accuracy and correctness in patient record matching is significant. A false positive, where two distinct patients are incorrectly merged into a single record, can lead to clinical harm, regulatory repercussions, and considerable patient distress. In contrast, a false negative, where the same patient is represented by multiple records, may cause fragmented care and administrative inefficiencies, consequences that are generally manageable in the short term. Therefore, the matching system should be calibrated to minimize false positives, even if this approach results in an increased rate of false negatives, which contrasts with calibration priorities in most other domains.
Temporally Changing Attributes - Match attributes can change over time. For instance, providers may move their practice locations repeatedly throughout their careers, patients might update their address, phone number, or even change their name, and device manufacturers could rebrand. The matching system must adjust for these shifts, recognising that an attribute valid when a record was created might later become outdated, and two records with differing addresses could still refer to the same entity.
Architectural Tenets of Lakehouse-Native MDM
The following solution tenets are the principles that, taken together, produce an MDM solution that is durable, auditable, and economically sustainable on Databricks.
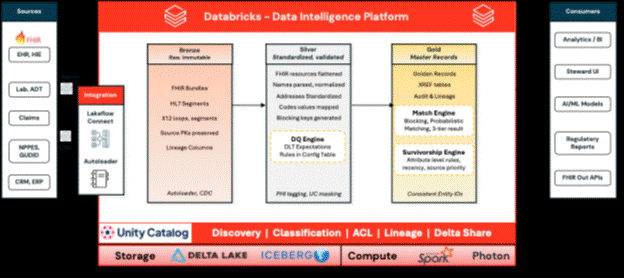
Fig 1: Lakehouse-native MDM Medallion Architecture with explicit MDM zones, governed end to end by Unity Catalog
Lakehouse-Native, Not Bolted On
All artefacts produced during the MDM pipeline, including source records, candidate match pairs, golden records, cross-reference tables, audit logs, and steward decisions, are stored as Delta tables within Unity Catalog. The system does not rely on an external database for operational state, which avoids issues with data movement, conflicting security models, and reconciliation across different platforms.
Medallion Layering with Explicit MDM Zones
Bronze retains complete source records with full lineage. Silver contains standardized, validated, and quality-assured data. Gold comprises golden records alongside a cross-reference table that links each source record to its master identifier. The cross-reference table is the primary asset of the MDM pipeline, as it ensures the golden record can be reproduced, audited, and reversed as needed.
Declarative Configuration, Not Embedded Code
Data quality rules, blocking strategies, match rules, and survivorship rules are stored as table configurations or version-controlled files in Git. A data steward or business analyst can add new rules without any engineering effort. This is the difference between an MDM platform that scales operationally and a one-off pipeline that requires a developer input for every change.
Stable, Deterministic Entity Identifiers
Entity identifiers are created just once and stored in a cross-reference table, remaining consistent during reprocessing, late-arriving data, and complete reloads. If a new source record matches an existing group, it inherits the current entity ID; only new groups of matched records get new IDs. The most frequent cause of lost confidence among downstream consumers in MDM implementations is unstable identifiers.
Blocking Before Matching
Pairwise comparison of all records is computationally infeasible at large scale. Therefore, every match pipeline requires a blocking strategy, which reduces the candidate pair space by orders of magnitude before applying similarity scoring runs. Common blocking techniques for patient matching include combining postal codes with surname, or using the first three letters of an email address together with the birth year.
Three-Tier Match Outcomes
Match outcomes are not limited to binary decisions. Pairs with high confidence are automatically merged, those with low confidence are rejected, and ambiguous cases are assigned for manual evaluation. The thresholds that define each tier are adjustable and should be reviewed regularly based on the steward feedback. A two-tier approach (auto-merge or auto-reject only) leads either to false positives or to fragmented data, depending on which way the threshold is set.
Unity Catalog as the Governance Substrate
Row-level filters, column masks, attribute-based access policies, lineage, and audit logging are all configured once in Unity Catalog and apply uniformly to every consumer, whether human or service principal. There is no alternate permissions model for MDM workloads, no shadow copy of data created for matching, and no exception path that bypasses central governance.
Where FHIR Meets the Lakehouse
Databricks supports several native patterns for ingesting healthcare-specific formats that are not natural fits for a general-purpose data platform.
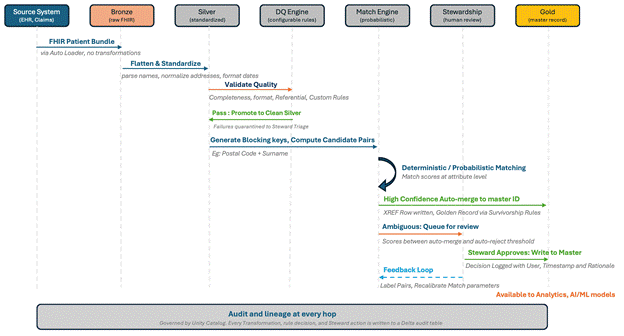
Fig 2 From FHIR Bundle to Master Record - The end-to-end journey of a Patient resource through MDM pipeline in Databricks
FHIR resources land in Bronze in their native JSON form through Auto Loader, which handles the schema evolution that comes with FHIR profile differences across source systems. The Bronze table preserves the original bundle structure, the source system identifier, and the ingest timestamp, so that any downstream processing can be reproduced from the original artefact.
In Silver, FHIR resources are flattened into normalized tables that align with the medallion model. The Patient resource produces a row in the standardized patient table, with names parsed into components, addresses validated and standardized, contact points normalized to consistent formats, and identifiers separated by type. Codes that arrive bound to specific terminologies are mapped to canonical references (SNOMED CT, LOINC, ICD-10, RxNorm) where the source provided them and flagged for review where it did not.
HL7 v2 messages follow a parallel path through dedicated parsers, and X12 EDI transactions (837 claims, 270 and 271 eligibility, 835 remittance) are similarly normalized into Silver tables that share the same downstream interfaces. The result is that the MDM pipeline downstream of Silver does not have to know which standard the data arrived in; it operates on standardized, quality-checked records regardless of source format.
This convergence is one of the more distinctive benefits of building MDM natively on Databricks. Most general-purpose MDM platforms treat healthcare-specific formats as an integration concern to be solved by an external middleware layer. A lakehouse-native pattern brings the standards-handling into the same governed environment as the matching, survivorship, and stewardship logic.
Data Quality, the Prerequisite for Matching
Matching dirty data is a futile exercise. If the original record lacks information, no match engine can recover it, and these engines will confidently give incorrect results when given with inconsistent or poorly formatted inputs. That’s why every credible MDM implementation treats data quality as the prerequisite for matching rather than as a downstream concern. The DQ engine sits in the Silver layer and acts as the gate through which records must pass before they reach the matching engine.
Categories of Healthcare DQ Rules
Five categories of rules cover the great majority of healthcare data quality concerns.
- Completeness rules verify that required attributes are present, with thresholds adjusted by record type. For example, a Patient record without a date of birth is unusable whereas a Patient record without a middle name is acceptable.
- Format rules verify that attributes conform to expected patterns, such as NPI being a ten-digit number with a valid Luhn checksum, or NDC being formatted as one of the recognized eleven-digit variants.
- Referential rules verify that coded values resolve against the appropriate terminology, such as a diagnosis code resolving against the current ICD-10 release.
- Consistency rules verify that combinations of attributes make sense, such as a date of service falling between a patient date of birth and the current date.
- Custom business rules cover organization-specific constraints that do not fit the standard categories, such as a provider taxonomy code being consistent with the credentialing record.
Declarative Rules, Executable Outcomes
Rules are set declaratively, either as Delta Live Tables expectations or in a rules table read by the pipeline at runtime. Each rule specifies a name, target table, SQL condition, severity (block, quarantine, warn), and remediation hint. The pipeline applies rules in order and generates an outcome table noting which records passed or failed each rule. This outcome table is used for steward queues, monitoring dashboards, and feedback loops to source systems.
Three Outcomes, Not Two
The DQ engine produces three outcomes per record. Records that pass all rules are promoted to clean Silver and forwarded to the matching engine. Records that fail blocking rules are quarantined and routed to a steward queue for triage and, where appropriate, correction at source. Records that fail warning rules are forwarded but flagged so that downstream consumers can apply their own judgement. The distinction matters because it preserves throughput while preventing low-quality data from contaminating the master record.
Continuous Monitoring, Not Periodic Audits
Data quality is continuously monitored through Lakehouse Monitoring and presented on a compliance dashboard managed directly by the data quality team, with no requirement for engineering involvement during routine reviews. A shift in the rate of rule failures over time frequently serves as an early indication that an upstream source system has undergone changes warranting attention.
For instance, if the rate of NPI format failures from a specific source increases from zero to two percent within a week, this typically suggests an alteration in how the source populates the field, indicating that remediation efforts should be directed upstream rather than within the MDM pipeline.
The investment in DQ pays back twice. The first return is in match quality, since clean inputs produce reliable matches. The second is in steward workload, since the records that reach the steward queue are ambiguous matches rather than data quality failures disguised as ambiguous matches.
The Matching Engine
The matching engine serves as the central component of the MDM pipeline, with the algorithm selection having a significant impact on downstream data quality. In healthcare settings, two primary characteristics are essential: the algorithm should be probabilistic and must offer explainability.
Why Probabilistic
Deterministic matching, which employs exact or rule-based comparisons of defined attributes, effectively resolves a subset of healthcare matching scenarios. For instance, precise matches on provider NPI, device UDI, or member ID combined with payer can address straightforward cases reliably. However, these approaches are insufficient for the more complex situations that comprise the majority of cases. Patient records with minor discrepancies, such as slight variations in first name spelling, transposed digits in birth dates, or changes in address, may pertain to the same individual. Developing and maintaining a deterministic rule set comprehensive enough to capture these instances is often impractical.
Probabilistic matching assigns a weight to the agreement or disagreement of each attribute based on its discriminating power. The weights derive from two probabilities: the probability that an attribute agrees given that the records are a true match, and the probability that the attribute agrees by chance. The aggregate score across attributes produces a match probability that can be interpreted directly and tuned with thresholds. The Splink library implements this approach natively on Spark and runs efficiently on Databricks at typical healthcare scales.
Why Explainable
Healthcare regulators, clinical safety committees, and individual patients have valid reasons for requesting clarification regarding why two records are merged or maintained separately. An algorithm that lacks the capacity to provide clear, concrete explanations is unsuitable for deployment in regulated healthcare environments. The algorithm’s scoring process inherently generates an explanation, as it enables both per-attribute weights and the aggregate score to be presented directly to stewards or auditors. Furthermore, match explanations should be documented alongside the match outcome itself to facilitate future reviews without necessitating recomputation.
Survivorship and the Golden Record
Survivorship is the discipline of producing a single golden record from a cluster of records that the matching engine has determined to describe the same entity. In a healthcare context, the rules that govern survivorship differ from the rules that suit most other industries, in ways that are worth being explicit about.
Clinical attributes are typically valued more for their recency than administrative ones. For instance, a recent patient address is preferable to an outdated one, while medication lists should be updated cautiously to avoid including discontinued drugs. Different survivorship rules are often used for clinical versus administrative data, with explicit version histories maintained for clinical information.
Authoritative source preference matters more than it does in other domains. For provider records, NPPES is the authoritative source for the practitioner name and the NPI, and the survivorship rule should reflect this regardless of which internal system was the most recent to update the record. For device records, GUDID is the authoritative source for the product identifier and the device description. Codifying these preferences as configuration is preferable to embedding them in code, since the authoritative reference data is itself subject to occasional change.
Merging records in healthcare MDM systems is handled more cautiously than usual. While a standard MDM tool might merge two entries based on a moderate similarity score, healthcare MDM typically keeps both records separate and waits for steward approval unless the similarity score reaches a high-confidence level. This careful approach is driven by the uneven risks involved, as previously discussed, and survivorship rules should be designed accordingly.
Stewardship as a Quality Function
Stewardship in healthcare MDM is not a data operations function. It is a clinical quality function, even when the staff who perform it sit organizationally within IT or data management. The decisions that stewards make affect the records that clinicians and operational staff act on, and the standards that apply to clinical quality apply with equal force to the steward workflow.
The stewards themselves are often clinical informaticists, registered nurses with informatics backgrounds, or experienced credentialing staff for the provider domain. They are typically not data engineers, and their tools should reflect that. The stewardship interface should present match candidates with their attribute-by-attribute comparison, the score and its explanation, the source records in human-readable form, and a clear set of actions (confirm match, reject match, request additional information, escalate).
Databricks Apps provides a viable surface for building this interface natively against the lakehouse, with Unity Catalog providing the access controls and audit logging.
The most consequential element of the stewardship workflow is the feedback loop. Every confirmed match and every rejected match becomes labelled training data, which is fed back into the match parameter estimation to improve the model over time. Without this loop, the steward queue grows linearly with data volume and the system never improves. With it, the system becomes progressively more accurate at the same time as the steward workload becomes more concentrated on genuinely difficult cases.
An effective steward operating model typically includes three main elements - a daily review queue with service levels that match the urgency of records being assessed, regular evaluation of threshold settings and performance metrics, and quarterly audits of survivorship rules and authoritative source preferences. While the specific timing of reviews is less critical, having a clear operating model is essential; without one, stewardship can become inconsistent and ultimately overlooked.
Governance, HIPAA, and the Audit Trail
Governance in healthcare MDM is integral to its technical architecture, and not a separate concern. The lakehouse-native pattern delivers key governance features by default, without needing an extra layer.
Unity Catalog applies row-level filters and column masks uniformly to every consumer, which means that the matching engine, the steward interface, and the downstream analytics workloads all see the same access-controlled view of the data. A steward who is not authorized to see substance use records does not see them in the steward queue, and an analyst who is not authorized to see provider compensation does not see it in the master record. This is enforced as a property of the platform rather than as a property of each application.
Lineage is captured automatically across tables, notebooks, dashboards, models, and AI agents, which means that the question of which source records contributed to a particular golden record can be answered through a query rather than through an investigation. The same lineage supports breach notification readiness: when an event occurs that requires the organization to identify which patients may have been affected, the lineage and the cross-reference table together support a parameterized query that produces the affected population on demand.
Every transformation, rule decision, match outcome, and steward action is written to a Delta audit table with the identity of the principal who performed it and the timestamp at which it occurred. Audit evidence is therefore a continuous data product rather than a discrete project commissioned in response to a regulatory request. The compliance team operates the audit dashboard directly, without requiring engineering involvement for routine review.
Refer our blog on establishing AI guardrails in Databricks for additional information.
Where to Start
Organizations that are early in their MDM journey will benefit from a deliberate, narrow first step rather than a comprehensive program launched at full scale. The recommendations below reflect the patterns that have worked in healthcare contexts.
Choose a single domain first, and choose it for value rather than for visibility.
- For most provider organizations, Provider MDM is the right first choice, since it has high operational value, well-defined authoritative external references in NPPES and the state license boards, and lower clinical risk than Patient MDM.
- For payer organizations, Provider MDM has similar advantages, and Member MDM is a credible alternative if the operational pain is acute.
- For diagnostics manufacturers and pharmaceutical companies, Product MDM combined with Customer MDM is often the highest-value combination, since it connects directly to commercial analytics and regulatory reporting.
Establish the medallion foundation before tackling the matching engine. The Bronze and Silver layers, the standardization logic, and the data quality engine deliver value independently of the matching engine and provide the clean inputs that the matching engine requires. Standing these up first lets the organization build operational muscle around data quality before the additional complexity of matching arrives.
Prove the matching engine on real data, not on synthetic data or vendor reference datasets. The peculiarities of any individual organization data including the source systems, the data quality history, the local conventions in naming and addressing will affect match performance more than any general claim about the matching algorithm. A focused proof of value on a representative sample produces a more reliable estimate of production behavior than any external benchmark.
Plan for stewardship from the start, not as a phase two activity. The most common failure mode in healthcare MDM is treating stewardship as something that can be added once the matching engine is in place. Stewardship operating model, steward identification and training, interface design, and feedback loop design are all activities that take time and benefit from being addressed in parallel with the engineering work.
