
A relational database has been the backend of business systems for many years. However, the past decade witnessed an evolution of Big Data that is bigger in volume and structurally varied, leading to the NoSQL movement. Volumes of customer data gathered from disparate sources had to be integrated to provide crucial insights. This could be possible only with a powerful, advanced database that can store, map, and query data relationships at a great speed – a database that helps understand the crucial focus points in an enterprise, incorporating dynamic information without the need of a pre-defined rigid schema.
To summarize, there was a need for a general database management technology that could embrace connected data and enable graph thinking. This technology is called the Graph Database. It should not be viewed as a “replacement” technology, but rather a complimentary piece to other databases that have already been deployed.
One of the main reasons for choosing a Graph Database is speed. The data processing speed is considerably high. A basic query, for example, can be executed hundreds of times faster. Since the schema is less rigid, fluctuating data can be handled quickly, rapidly, and naturally. Records can be accessed in a fraction of a second since each element is linked to the other by each edge. Moreover, graph databases can handle volumes of data quickly when compared to relational databases.
This blog post gives an overview of graph databases, the need for graph databases, and touches on graph models and their properties, use cases, merits, and demerits.

What is a Graph Database?
A graph database is data management system software that has vertices (nodes) and edges as the building blocks instead of tables.
There are four types of NoSQL databases, and one of them is the graph database. The key differentiator between these types of new databases is the data model that they use. The data model is basically the building block that is exhibited to the developer. The building block of a graph database is that of nodes, typed relationships between nodes and key value properties that can be attached to both the nodes and to the relationship or be associated with their own attributes. For example; if there are two parties, x and y, who engaged in a conversation, X is a node and y is also a node, and between them is a relationship called “in a conversation”.
The basic idea is that for each party, the graph will break out and show the relationships between the parties. To refer to the above example; X has a relationship with Y who is engaged in a conversation. The graph feature will visually show the relationship.
Graph database management systems offer Create, Read, Update, and Delete (CRUD) methods to access and manage data. Graph databases can be used for both OLAP and OLTP (Online Transaction Processing). Systems tailored to OLTP are generally optimized for transactional performance, guaranteeing the ACID properties.
What are Some Possible Graph Database Projects?
Graph Databases are great for social applications and have gained a great popularity from social networking models. One of the well-known examples is the Facebook Graph Search. Facebook’s search app, called as the third pillar of Facebook, has a new way of searching social graphs.
There is also a broad applicability of graph databases outside of social. They are used in master data management, network management, content management, CRM systems, online recommendations, virtual assistants to drive conversations, artificial intelligence, machine learning, security, and fraud detection.
Master Data Management/Customer 360
Understand and analyze business data and their relationships, consolidated across various business units to acquire a holistic customer view.
Recommendation
Influence customers to buy company products and recommend to others.
Security and Fraud Detection
Determine the fraudulent entity, transaction, or interaction that poses a security risk or compliance issue.
When should you use a Graph Database?
A graph database cannot be applied at all situations. The requirements have to be evaluated every time based on the situation.
Data Model
One of the major criteria for determining if the graph database can be applied is by evaluating your data model. If the data model is highly relational, a graph database is the best fit. The general-purpose structure allows you to model all kinds of scenarios
Relationship Type
If your data contains many-to-many relationships, a graph database is preferable. A graph database is also easier to represent in the case of one-to-many relationships. Graph databases represent the related data inherently as it is and eliminates “Join” performance issues. Since relationships take priority, applications need not infer data connections using foreign keys.
Schema
If your schema is not absolutely rigid, then a graph database is the best fit even if a relational database suits your requirement. The property graph model database, one of the most popular variants of the graph database model, is schema-less and optimized for traversal.
Data Analysis
If your data involves complex analysis or expensive queries spanning multiple types of data, a graph database is the best choice to run the queries more efficiently.
How do Graph Databases Work?
The graph model works particularly well for applications where connections between items of data are the most essential factor. Connected data is more important than individual points. Relationships and connections are persisted through every part of the data cycle.
Graph model has two primary components: Nodes (entities) and edges (relationships between entities). Nodes are the entities in the graph. They can have properties or attributes (key-value). Relationships have a start and end node. They can also have labels assigned to it representing their roles in that domain. The main purpose of a Graph Database is analysis and visualization of graphical data. In a graph database, you typically index properties to find start points.
The way you would move around a graph is to traverse along specific edge types, or across the entire graph. Traversing is nothing but the act of journeying through nodes in the graph. Traversing to nodes via their relationships is similar to the JOINs on the relational database tables, but these traverses are quicker than the JOINs. Since relationships are stored in the graph itself, retrieval of information from nodes is easier. The graph takes into account only the data that is needed without considering any grouping operations on the entire dataset while querying. The performance of the data being queried is based on the data being queried and not on the size of the dataset. Since relationships and connections are persistent through the entire data lifecycle, there is no reliance on a foreign key for lookups in tables.
Unique Characteristics
The following are two properties that make graph databases unique:
Storage
Graph storage refers to the underlying structure of the database that contains graph data. It can be classified into Native and Non-Native Storage.
- Native Storage
Some graph databases use native graph storage that is specifically designed to store and manage graphs. The graph database is populated with technology designed to be graph-first. - Non-Native Storage
Databases are bolted as an after-thought. Storage comes from an outside source such as a relational database, an object-oriented database, or some other general-purpose data store. This type of storage is slower than a native approach because all the graph connections have to be translated into a different data model.
Processing
Graph processing can also be classified into Native Graph Processing and Non-Native Graph Processing.
- Native Graph Processing
Connected nodes physically point to each other in a native graph processing; this is the most efficient means of processing data in a graph. It is also known as index-free adjacency because each node directly references the nodes adjacent to it. - Non-Native Graph Processing
Non-native graph processing often uses a larger number of indexes to complete a read or write transaction, significantly slowing down operations.
What are Graph Databases good for?
A graph database is good for quoting a graph and interpreting a graph. Graph databases are applicable when there is a need for fast, iterative development to meet the open-ended business requirements.
- Recommendations
Recommendation engines depend on finding objects having similar properties. But as the volume and complexity grows, the underlying system architecture also becomes more complex. Graph Databases can perform sophisticated relationship-based queries in real time to analyze customer behavior at the point of transaction. - Highly-Connected Data (Social Networks):
Perhaps the most common use case for a graph database is social networks, with their perplexing connections and user activity. - Anomaly Detection
A quick analysis of data relationships is essential to uncover fraud in real time, and graph databases provide the necessary performance. - Metadata-based Content Management
Content can be annotated automatically and transformed to a knowledge base - Knowledge Graphs
Used by search engines and businesses alike, knowledge graphs accumulate data from a wide variety of sources, allowing for better digital asset management and easier information retrieval. For example, Google tries to gather the knowledge in the universe into one big graph, so when you do a search for a person X, you will get all the classic text search results, which is based on a full-text query ordered by Pagerank in a simplified way. You also tend to get additional results around the search keyword. - Systems Management
Graph databases can be used by enterprise customers to map communications or IT networks and run complex scenario testing, to prepare for outages in a better way. - Identity Management
Graph databases are more dynamic by nature, can track changing roles better, and access authorizations more efficiently than traditional systems.
Disadvantages
Graph databases are not as helpful for operational use cases because they are not efficient at processing high volumes of transactions and they are not good at handling queries that span the entire database. They are not optimized to store and retrieve business entities such as customers or suppliers, which is why you would need to combine a graph database with a relational or NoSQL database.
A graph database is just a data store and does not give you a business-facing user interface to query or manage relationships nor will it provide survivorship functionality or data quality capabilities.
Graph databases do not create better connections but retrieve data at a faster pace for connected data.
Popular Examples of Graph Databases
A lot of graph databases, tools, and frameworks have sprung up in the past few years, and a majority of them are open source. Here are the few of the popular ones:
• Titan
• ArangoDB
• Neo4j
• AnzoGraph
• AllegroGraph
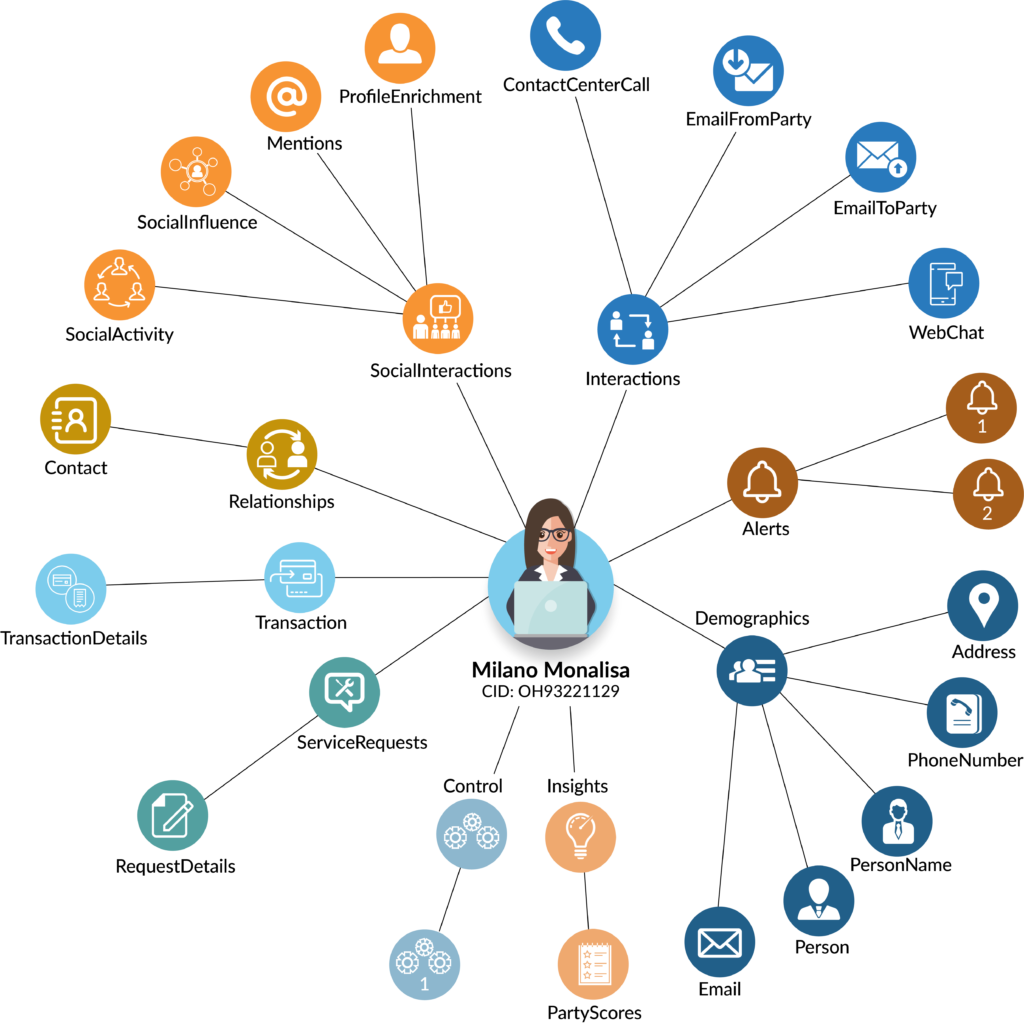
Mastech InfoTrellis’ Approach to Graph Database
Mastech InfoTrellis can help create a Customer 360 view from data received from disparate sources.
- Customer-related data links are provided to easily view the graph network of the Customer 360 page. Create customer context, ascertain connection between parties, and understand how they are inter-related.
- Business users can view the connection between multiple parties.
- Enables business users to search for their customers and find relationships to any other data attributes related to that customer (other customers, products, competitors, concepts, places, events, or anything else).
- Hierarchies of multiple entities can be visualized in a single Customer 360 dashboard.
- Business users can visually see all the relationships created for that customer.
- Enables a 360° visual representation of the relationship between entities using the data.For example, marketing teams can start exploring relationships between objects of interest using the data and use this information to drive targeted marketing messaging and campaigns.
Having a graph database in the picture saves a lot of time when creating composite views(collection of connected or related source keys).
Conclusion
Graph databases solve today’s data challenges by focusing not only on data, but also on the connections or relationships between individual database entries. They have various use cases and are available both as community-driven software products and as commercial software with enterprise-grade support.

Aradhana Pandey
Technical Consultant




















